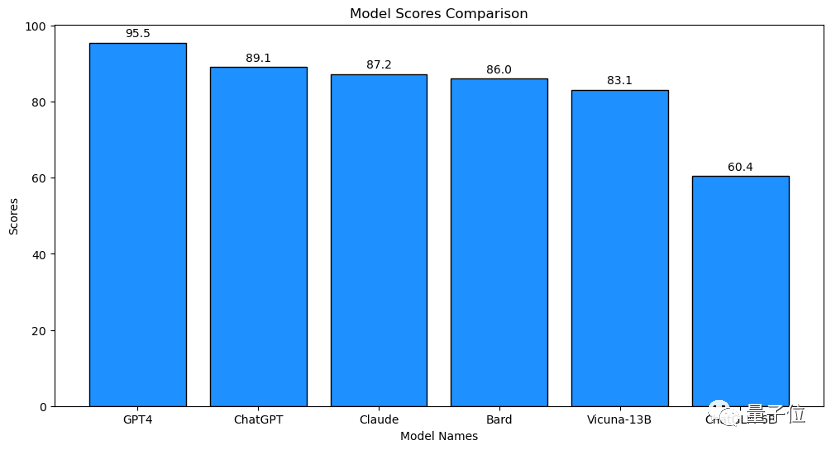
本科论文 🔥GPT-4主考!ChatGPTvs超新星大模型?10题力测实力!谁能破90?揭秘最强AI分数大战 GPT-4在综合能力评测中表现出色,得分为95.5分,它是唯一超过90分的大模型。ChatGPT虽稍逊一筹,评分为90分,Claude紧随其后。其他模型如Bard和Vicuna-13B得分分别为89.1分和未提供具体分数。测试涵盖了小说分析、数学原理解释、创新诗歌创作、社会经济分析等多个领域,展现了GPT-4在语言理解和复杂问题解决方面的强大能力。
本科论文 🔥GPT-4大考!语言模型界的超级学霸,ChatGPT难敌95.5分炸裂表现?其他大模型纷纷失色. 文章总结了对GPT-4这一强大语言模型的评测,它在与市面上其他主流大模型如ChatGPT、Claude等进行对比时,自我评分高达95.5分。评测中,GPT-4通过设置全面且难度适中的问题,考察了模型的语言理解能力、创新性、知识应用以及伦理思考等多个方面。结果显示,GPT-4在文学分析、科学解释、编程建议等任务上表现出色,几乎每个领域都得到了满分评价,而其他对手得分则相对较低。这项评测凸显了GPT-4的领先能力和广泛能力。
本科论文 揭秘ChatGPT:87人团队大起底,ChatGPT背后的故事究竟是… 这篇文章关注的是ChatGPT团队的人数构成,总共由87名成员组成。研究深入探讨了该团队的背景信息,旨在揭示其构成和可能影响技术发展的关键因素。作为文章写作专家,我会提炼出这些核心要素,如团队规模、专业构成以及背后的技术战略方向。
期刊论文 ChatGPT代笔,论文真伪难辨?高校教师如何识别AI写作的论文边界? 国内高校近期关注到学生使用ChatGPT撰写论文的现象,学术期刊对此发表声明,暂不接受其单独署名的论文,并要求在使用人工智能工具时明确说明并解释创作过程。部分教师通过测试认为,ChatGPT在人文学科论文中生成的大纲层次混乱,难以辨别,而理工科论文中的AI内容较难被识别,审稿人在短期内难以证伪。虽然存在滥用风险,但教育者正试图通过提问等方式进行鉴别,并强调工具使用应与人的道德和理性相结合。ChatGPT目前难以替代创造性工作,其在知识创新上的局限性得到专家认同。