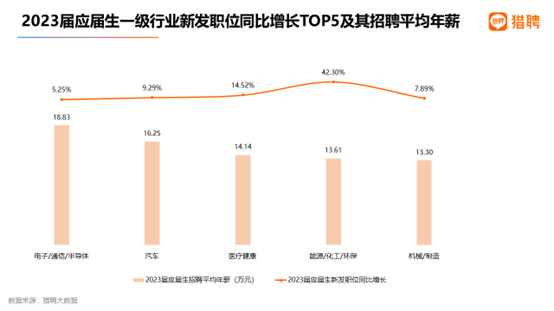
ChatGPT惹到医学生,博导:没事,它不能替你去手术台
最近有一种感觉,一到6月,周围好像就按下了加速键。 上半年马上过完,这个月赶上高考、中考、毕业、入职,有的人面临着人生的岔路口,还有人紧赶慢赶地调整自己的生活节奏。 好像大家都有忙不完的事情。 或许,在这样一种承上启下的转折点,很多人忙碌的,不只是做不完的事情,更是压在心里的一份不确定感。 不过,在不确定之外,生活中值得停留的事情还有很多—— 比如,鲜花,流云,健康与快乐。 嘻嘻,还有接下来每个月都会共同回顾的,全球视野~ 下面进入本月主要内容>>> 01 杨紫琼:人生不受限 不知不觉,就到了毕业季,许多人都在思考,接下来的路该怎么走。 这个问题,或许首位亚裔奥斯卡影后杨紫琼很有发言权叭~ 5月24日,杨紫琼参加了哈佛大学法学院的毕业典礼,在讲台上金句频出: “换句话说,知道自己的不足,能让你获得别人的尊重;而别人给你设定的限制,是用来突破的界限。” 杨紫琼在演讲的时候,回顾了自己的经历,她会成为演员,可谓“歪打正着”—— 最开始,她是个学舞蹈的小姑娘,梦想是当一个出色的舞蹈家。 可惜,因为脊柱伤病,她只能放弃舞蹈。 兜兜转转到香港后,偶然拍了广告,才意外进入电影圈。 所以,不要轻易给自己的人生设限! 每个人的人生有无限可能,敢想敢做没什么不好意思的,多多尝试,万一哪天就实现了呢? 说不定,这一次跌倒,爬起来之后就是一片新天地吖~ 02 塞尔达会惩罚所有不好好学物理的“小笨蛋” 没想到,初高中物理课上摸的鱼,都会在玩游戏的时候被“报复”回来。 自从任天堂的新游戏《塞尔达·王国之泪》发布后,很多人发现了个新功能—— “究极手”,可以搭配组装在游戏里搜刮来的各种材料。 结果,同样的功能,在不同人手上却天差地别: 有的网友已经在视频里秀起了炫酷的轰炸机,一举让海拉鲁大陆进入工业时代; 图源:B站 @咸鱼小叔叔 有的人却因为没考虑到受力分析,车子走着走着就把自己埋了。 图源:Twitter @LegendsOfPrince 最让人破大防的是,有人费劲千辛万苦才做好一个小木车,却在用斧头启动木车后面的小风扇时,一斧子把木头车劈散架了。 图源:B站 @A9VG 大家忙着各种整活,恶补物理知识。 至于游戏主线? 救公主是吧?!还在造车呢,晚点再说! 03 马斯克这把整了高端局 有些东西,看到的时候真的会让人感到震惊。 比如,最擅长整活的马斯克,最近打算搞的人形机器人“Optimus”。 5月17日,特斯拉开股东大会,马斯克在会上放了个视频。 几个浑身泛着金属光泽的机器人,正灵活地走动。 图源:Twitter...