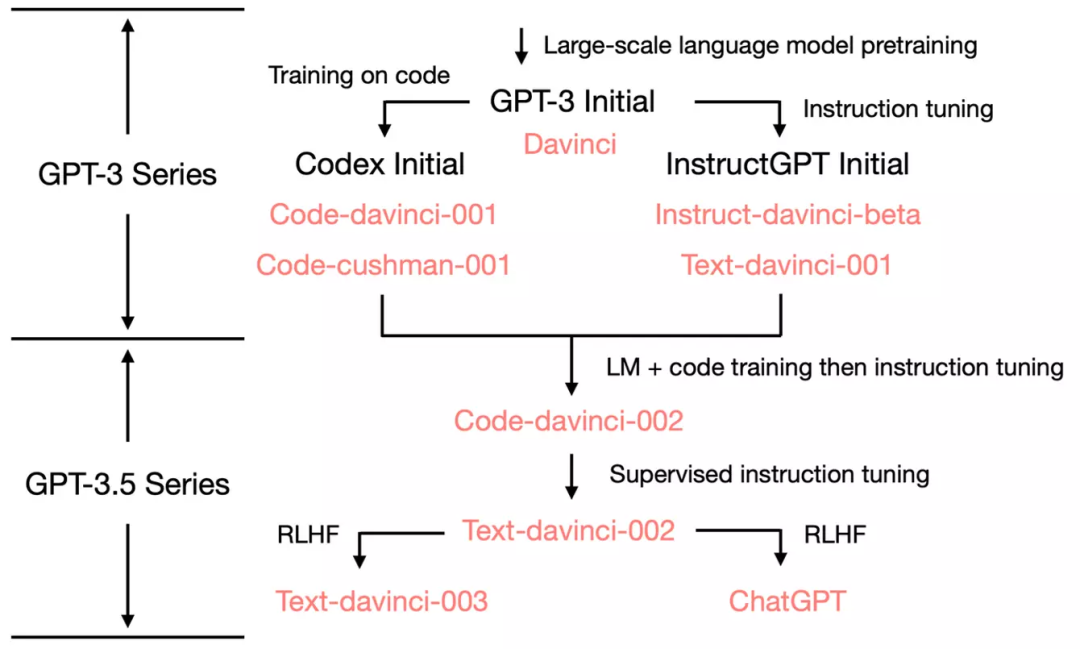
研博论文
关注【AI商业精选】,带你早半步认知这个复杂的世界!我们会有专业的团队为你从海量信息中精选AI商业文章。限时免费:我们开发了一款GPT聊天机器人(无需魔法、不限聊天次数),如果你希望免费领取7天试用,可以关注公众号回复【668】。AI主编?要点提炼——AI商业精选1.GPT-3.5系列的语言能力、世界知识和上下文学习能力来自于davinci预训练模型。2.GPT-3.5系列遵循指令和泛化到新任务的能力来源于大规模指令学习。3.GPT-3.5系列的对话能力和生成中立的回答能力来源于与人类的对齐,无论是监督学习方式(text-davinci-002)还是强化学习方式(text-davinci-003)。+1.code-davinci-002似乎是GPT-3.5系列中能力最强的模型,因为它综合了代码训练和指令微调的效果。以下为正文内容,Enjoy:作者:符尧 彭昊 Tushar Khot编辑:LRS 好困最近OpenAI发布的ChatGPT给人工智能领域注入了一针强心剂,其强大的能力远超自然语言处理研究者们的预期。体验过ChatGPT的用户很自然地就会提出疑问:初代GPT 3是如何进化成ChatGPT的?GPT 3.5惊人的语言能力又来自哪?最近来自艾伦人工智能研究所的研究人员撰写了一篇文章,试图剖析 ChatGPT 的突现能力(Emergent Ability),并追溯这些能力的来源,并给出了一个全面的技术路线图以说明 GPT-3.5 模型系列以及相关的大型语言模型是如何一步步进化成目前的强大形态。原文链接:https://yaofu.notion.site/GPT-3-5-360081d91ec245f29029d37b54573756作者符尧是2020年入学的爱丁堡大学博士生,硕士毕业于哥伦比亚大学,本科毕业于北京大学,目前在艾伦人工智能研究所做研究实习生。他的主要研究方向为人类语言的大规模概率生成模型。作者彭昊本科毕业于北京大学,博士毕业于华盛顿大学,目前是艾伦人工智能研究所的Young Investigator,并将于2023年8月加入伊利诺伊大学厄巴纳-香槟分校计算机科学系,担任助理教授。他的主要研究方向包括使语言 AI 更有效率和更容易理解,以及建立大规模的语言模型。作者Tushar Khot博士毕业于威斯康星-麦迪逊大学,目前是艾伦人工智能研究所的研究科学家。他的主要研究方向为结构化机器推理。一、2020 版初代 GPT-3 与大规模预训练初代GPT-3展示了三个重要能力:语言生成:遵循提示词(prompt),然后生成补全提示词的句子。这也是今天人类与语言模型最普遍的交互方式。上下文学习 (in-context learning):遵循给定任务的几个示例,然后为新的测试用例生成解决方案。很重要的一点是,GPT-3虽然是个语言模型,但它的论文几乎没有谈到「语言建模」 (language modeling) —— 作者将他们全部的写作精力都投入到了对上下文学习的愿景上,这才是 GPT-3的真正重点。世界知识:包括事实性知识 (factual knowledge) 和常识 (commonsense)。那么这些能力从何而来呢?基本上,以上三种能力都来自于大规模预训练:在有3000亿单词的语料上预训练拥有1750亿参数的模型( 训练语料的60%来自于 2016 – 2019 的 C4 + 22% 来自于 WebText2 + 16% 来自于Books + 3%来自于Wikipedia)。其中:语言生成的能力来自于语言建模的训练目标 (language modeling)。世界知识来自 3000...