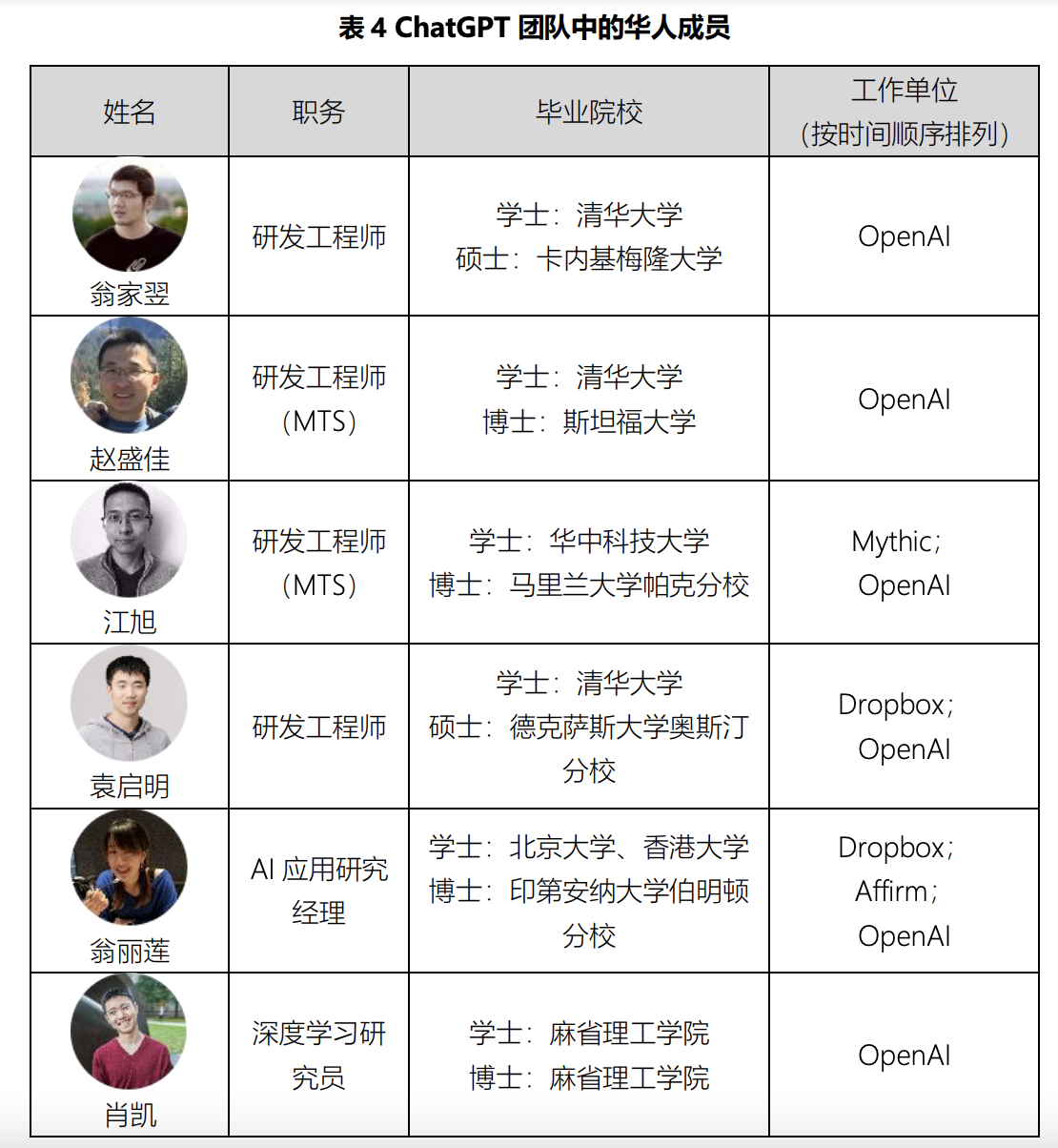
本科论文
人工智能正在把我们带入一个新纪元,从很多维度看都是如此。 首先是一个叫作“人工智能生成内容”(Artificial Intelligence Generated Content,AIGC)的概念开始得到认可。它区别于之前的用户生产内容(User Generated Content,UGC),也不同于更早期的专业机构生产内容(Professionally Generated Content,PGC)。这个历程既表明了内容生产主体的切换,意味着具备生产能力和掌握发布权力的主体,正在从象征着“内容民主化”的个人,转移到善用AI辅助创作的“超级个体”——甚至可以是独立工作的AI本身;同时,它也意味着,AI能施展魔法的疆域正在跨越一个分界点:从“判别式领域”迈入“生成式领域”。 过去,AI被认为只能做好判别性的工作。比如,判断一张图片中的人脸是不是特定的某人,一封来自未知地址的邮件是否为垃圾邮件,一篇分享到社交网络中的文章是否带有负面情绪,或者在一辆自动驾驶汽车前面晃动的到底是需要避开的真人还是无须在意的树影。 2022年面世的两个文生图产品改变了人们对AI的能力偏见。一个是DALL·E 2,发布者是后来因推出ChatGPT闻名的硅谷初创公司OpenAI。另一个是Stable Diffusion,出自位于伦敦、同样是初创公司的Stability AI之手。两个产品的图片生成水平第一次让业界看到商用可能。此前,业界最优秀的图像生成工具是生成对抗网络(Generative Adversarial Network,GAN),只能生成特定图片——比如人脸,换成小狗就不行,得重新训练——DALL·E 2和Stable Diffusion没有这种局限性。 上一个让业界看到商用可能并大获成功的AI技术是图像识别。2015年,基于深度学习的计算机视觉算法在ImageNet数据库里的识别准确率首次超过人类。此后,人脸识别系统迅速取代数字密码,成为最新潮的身份标识;可识别商品的自助结算系统也很快进入各类线下门店;连追求安全至上的自动驾驶都用上了AI的视觉判断。 Stable Diffusion和DALL·E 2的商业前景毋庸置疑,但它们关于AI新时代的开启充其量只是报幕员,ChatGPT才是主角,因为只有它解决了语言问题——起码看起来如此。 语言问题的解决意味着新的交互革命,这是AI新纪元的另一个涵义。 科幻作家特德·姜(Ted Chiang)体验ChatGPT后,将其背后的AI模型(GPT)比作互联网的“有损压缩”,意思是,当它学习了所有网上文字的统计规律后,就相当于获得了一个互联网信息的压缩版本——信息有所损失,但没那么多,重要的是,我们需要保存的文件更小了。假使外星人袭来,互联网毁灭,只要GPT还在,理论上我们能通过询问它获得原本存储在互联网上的所有东西。 事实上,不用幻想外星人入侵,特德·姜想象的这一天可能在不久之后就会到来。当人们可以用自然语言与机器交流,而机器不仅听得懂这些自然语言,还能与人对话、按照人的话语行事——回答人的问题、画一幅画或者创作一个视频、生成一款游戏,根据反馈意见再次修改,直到提出需求的人满意为止——这时候,每个人的电脑、手机上还需不需要安装那么多应用软件就值得重新考虑。也许,只留一个ChatGPT就够了。 此刻,相信你对无论ChatGPT还是更大范畴的AIGC到底意味着什么已有足够感知,可能也听过不少业界的溢美之词,比如英伟达创始人黄仁勋称现在为“AI的iPhone时刻”,比尔·盖茨认为AI革命的重要性不亚于互联网的诞生,微软CEO纳德拉则表示这种技术扩散堪比工业革命。 我们打算就此打住,不再过多陈述包括ChatGPT在内的生成式AI可能掀起的产业革命——本期杂志的其余几篇文章会继续从不同视角讨论它。这里,我们后退一步,走到AIGC尤其ChatGPT的背后,看看这些最新出圈的AI明星究竟站在怎样的基石之上。 01 Transformer的力量 ChatGPT发布之后,OpenAI团队成员接受采访,说公众的热情程度让他们意外,因为“ChatGPT背后的大部分技术并不新鲜”。这一说法属实,外界与之类似的总结是:ChatGPT是一种新时代的“炼金术”,把一个语言统计模型和基于人类反馈的强化学习放在一起,然后就是用可以拿到的语料、估计可行的人工神经网络层数放在一起“炼丹”。 但相较于2018年以前的AI模型,ChatGPT背后的GPT至少有一样东西是新的,那就是看待语言问题的视角。 人下一个会说出口的词,往往是统计学上下一个最可能出现的词——这个理念在语言学界早已有之,但将这种想法开发成对话语言模型是第一次。在此之前,几乎所有号称使用自然语言与人对话的机器人,从百度小度到微软小冰,从亚马逊Alexa到苹果Siri,甚至拿到日本公民身份的Sophia,本质上都是基于搜索树的查询系统。而自然语言处理(Natural language processing,NLP)领域也被工程化地划分为文本分类、机器翻译、阅读理解、文章分级等数十种任务,每种任务都对应一种或几种算法模型。 这些看似不同的问题背后其实是同一个问题。比如,如果一个对话机器人“足够聪明”,聪明到可以在电影评论中预测下一个单词,那么它一定能完成一个简单的正负分类任务,成为一个电影分类器——区分动画片、爱情或者科幻电影——接管之前判别式AI所做的工作。 通关密码就是2017年Google Brain团队写在论文里的Transformer(转换器),GPT的历代模型都基于这一算法架构。工作时,它会计算每个词与之前输入和生成的其他词之间的依赖关系(通常被称作“自注意机制”)。在最新发布的版本GPT-4中,模型能够注意到的单词量多达24576个。 Transformer认为,语言的内部数据之间长跨度地相互依赖,Transformer所做的工作,就是将既有文字的“内部依赖关系”转换到未来的文字中去,也就是“生成”。 信息内部的基本要素之间相互依赖,且具有预测功能——这种看待语言的视角之后也被用到了图片上。2021年,Google Brain团队再次推出一个叫“视觉转换器”(Vision Transformer,ViT)的模型,通过计算同一图像中像素与像素之间的依赖关系来识别图像。 在此之前,语言和视觉被视为不同的东西。语言是线性的、序列的,视觉则是一种有空间结构的、并行的数据。但Transformer证明,图片也可以当成序列问题来解决,一张图片就是由像素起承转合地构成的句子。 不仅图片,大部分问题都可以转化为序列问题。不要小看这种思维的转变。2018年,DeepMind发布的AlphaFold具有预测蛋白质结构的能力,靠的就是对氨基酸序列的学习,其背后架构也是Transformer。 02 语言的价值...