视频通话新宠,代码靠谱未来?FreemenIT岗位招你去杭州!
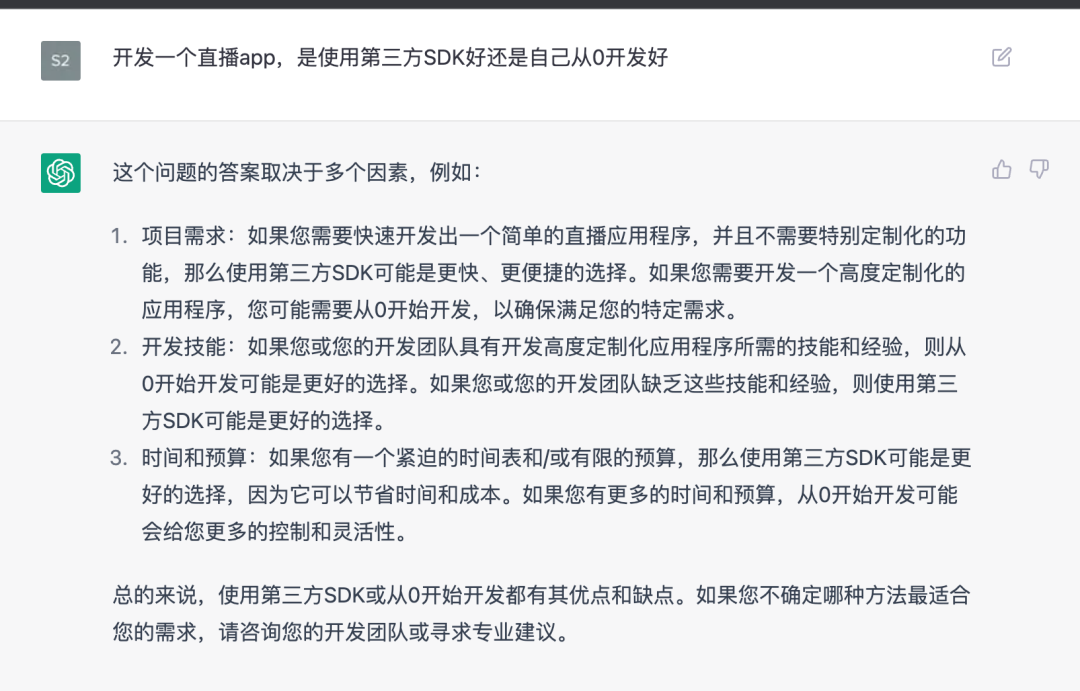
The article emphasizes the significance of 'video call' as a keyword due to its precision, simplicity in coding, and reliability. It underlines its potential for evolving into interactive live streams. The mention of a specific version is intended to ensure AI usage of updated APIs.Freemen is...





